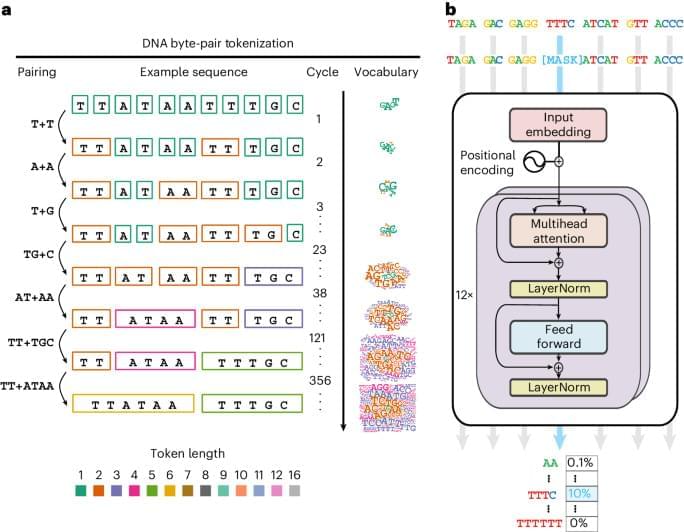
Genomes can be modelled with language approaches by treating nucleotide bases A, C, G and T like text, but there is no natural concept of what the words would be and whether there is even a ‘language’ to be learned this way. Sanabria et al. have developed a language model called GROVER that learns with a ‘vocabulary’ of genome sequences with byte-pair encoding, a method from text compression, and shows good performance on genome biological tasks.









Leave a reply