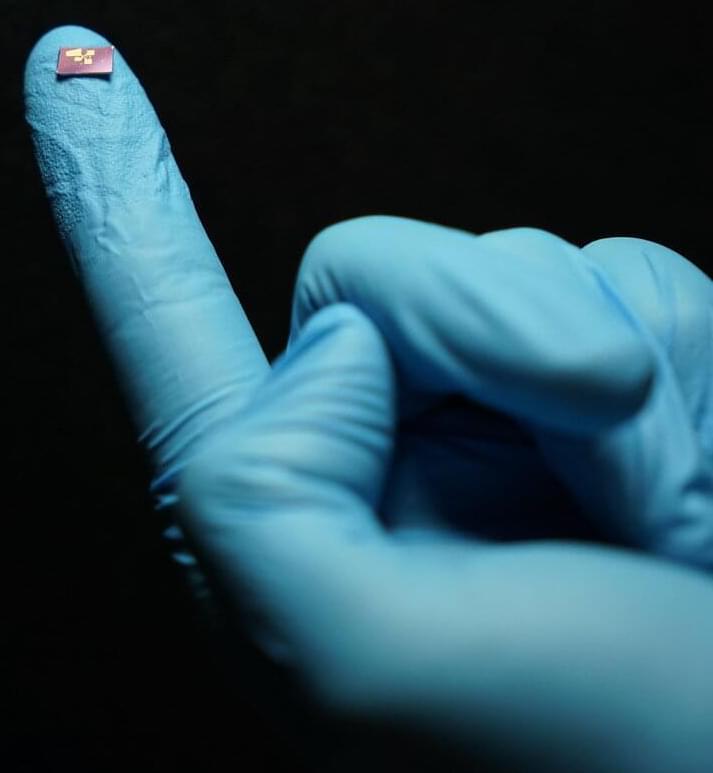
Scientists including an Oregon State University materials researcher have developed a better tool to measure light, contributing to a field known as optical spectrometry in a way that could improve everything from smartphone cameras to environmental monitoring.
The study, published today in Science, was led by Finland’s Aalto University and resulted in a powerful, ultra-tiny spectrometer that fits on a microchip and is operated using artificial intelligence.
The research involved a comparatively new class of super-thin materials known as two-dimensional semiconductors, and the upshot is a proof of concept for a spectrometer that could be readily incorporated into a variety of technologies—including quality inspection platforms, security sensors, biomedical analyzers and space telescopes.
If you’ve been closely following the progress of Open AI, the company run by Sam Altman whose neural nets can now write original text and create original pictures with astonishing ease and speed, you might just skip this piece.
If, on the other hand, you’ve only been vaguely paying attention to the company’s progress and the increasing traction that other so-called “generative” AI companies are suddenly gaining and want to better understand why, you might benefit from this interview with James Currier, a five-time founder and now venture investor who cofounded the firm NFX five years ago with several of his serial founder friends.
Currier falls into the camp of people following the progress closely — so closely that NFX has made numerous related investments in “generative tech” as he describes it, and it’s garnering more of the team’s attention every month. In fact, Currier doesn’t think the buzz about this new wrinkle on AI isn’t hype so much as a realization that the broader startup world is suddenly facing a very big opportunity for the first time in a long time. “Every 14 years,” says Currier, “we get one of these Cambrian explosions. We had one around the internet in ’94. We had one around mobile phones in 2008. Now we’re having another one in 2022.”
On Sunday, October 9, Judith Racusin was 35,000 feet in the air, en route to a high-energy astrophysics conference, when the biggest cosmic explosion in history took place. “I landed, looked at my phone, and had dozens of messages,” said Racusin, an astrophysicist at NASA’s Goddard Space Flight Center in Maryland. “It was really exceptional.”
The explosion was a long gamma-ray burst, a cosmic event where a massive dying star unleashes powerful jets of energy as it collapses into a black hole or neutron star. This particular burst was so bright that it oversaturated the Fermi Gamma-ray Space Telescope, an orbiting NASA telescope designed in part to observe such events. “There were so many photons per second that they couldn’t keep up,” said Andrew Levan, an astrophysicist at Radboud University in the Netherlands. The burst even appears to have caused Earth’s ionosphere, the upper layer of Earth’s atmosphere, to swell in size for several hours. “The fact you can change Earth’s ionosphere from an object halfway across the universe is pretty incredible,” said Doug Welch, an astronomer at McMaster University in Canada.
Astronomers cheekily called it the BOAT—“brightest of all time”—and began to squeeze it for information about gamma-ray bursts and the cosmos more generally. “Even 10 years from now there’ll be new understanding from this data set,” said Eric Burns, an astrophysicist at Louisiana State University. “It still hasn’t quite hit me that this really happened.”
Over the last three decades, the digital world that we access through smartphones and computers has grown so rich and detailed that much of our physical world has a corresponding life in this digital reality. Today, the physical and digital realities are on a steady course to merging, as robots, Augmented Reality (AR) and wearable digital devices enter our physical world, and physical items get their digital twin computer representations in the digital world.
These digital twins can be uniquely identified and protected from manipulation thanks to crypto technologies like blockchains. The trust that these technologies provide is extremely powerful, helping to fight counterfeiting, increase supply chain transparency, and enable the circular economy. However, a weak point is that there is no versatile and generally applicable identifier of physical items that is as trustworthy as a blockchain. This breaks the connection between the physical and digital twins and therefore limits the potential of technical solutions.
In a new paper published in Light: Science & Applications, an interdisciplinary team of scientists led by Professors Jan Lagerwall (physics) and Holger Voos (robotics) from the University of Luxembourg, Luxembourg, and Prof. Mathew Schwartz (architecture, construction of the built environment) from the New Jersey Institute of Technology, U.S., propose an innovative solution to this problem where physical items are given unique and unclonable fingerprints realized using cholesteric spherical reflectors, or CSRs for short.
Edward Boyden is a Hertz Foundation Fellow and recipient of the prestigious Hertz Foundation Grant for graduate study in the applications of the physical, biological and engineering sciences. A professor of Biological Engineering and Brain and Cognitive Sciences at MIT, Edward Boyden explains how humanity is only at its infancy in merging with machines. His work is leading him towards the development of a “brain co-processor”, a device that interacts intimately with the brain to upload and download information to and from it, augmenting human capabilities in memory storage, decision making, and cognition. The first step, however, is understanding the brain on a much deeper level. With the support of the Fannie and John Hertz Foundation, Ed Boyden pursued a PhD in neurosciences from Stanford University.
The Hertz Foundation mission is to provide unique financial and fellowship support to the nation’s most remarkable PhD students in the hard sciences. Hertz Fellowships are among the most prestigious in the world, and the foundation has invested over $200 million in Hertz Fellows since 1963 (present value) and supported over 1,100 brilliant and creative young scientists, who have gone on to become Nobel laureates, high-ranking military personnel, astronauts, inventors, Silicon Valley leaders, and tenured university professors. For more information, visit hertzfoundation.org.
TRANSCRIPT
Edward Boyden: Humans and machines have been merging for thousands of years. Right now I’m wearing shoes, I have a microphone on my jacket, we all probably used our phones at least once today… And we communicate with the augmentation of all sorts of amplification and even translation technologies: You can speak into a machine, and it’ll translate the words you’re saying in nearly real time.
So I think what might be different in the years to come is a matter of degree, not a matter of kind. One concept that I think is emerging is what I like to call the brain coprocessor, a device that intimately interacts with the brain. It can upload information to the brain and download information from it. Imagine that you could have a technology that could replace lost memories or augment decision making or boost attention or cognition. To do that though we have to understand how the brain works at a very deep level.
Although over a third of a million patients have had brain implants or neural implants that stimulate the nervous system, so far they’ve operated in an open-loop fashion. That is, they drive activity in the brain, but not in a fully-responsive fashion. What we want to do is to have bi-directional communication to the brain: Can you read and write information continuously, and supply—maybe through coupling these interfaces to silicon computers— exactly the information the brain needs?
The new research saw scientists follow 100,000 participants in the UK Biobank national cohort.
Smartphones could soon be used to predict populations’ mortality rates, according to a press release by PLOS Digital Health.
Previous studies have used measures of physical fitness, including walk tests and self-reported walk pace, to predict individual mortality risk. Now scientists are taking it a step further.
A collaborative research team co-led by City University of Hong Kong (CityU) has developed a wearable tactile rendering system, which can mimic the sensation of touch with high spatial resolution and a rapid response rate.
The team demonstrated its application potential in a braille display, adding the sense of touch in the metaverse for functions such as virtual reality shopping and gaming, and potentially facilitating the work of astronauts, deep-sea divers and others who need to wear thick gloves.
“We can hear and see our families over a long distance via phones and cameras, but we still cannot feel or hug them. We are physically isolated by space and time, especially during this long-lasting pandemic,” said Dr. Yang Zhengbao, Associate Professor in the Department of Mechanical Engineering of CityU, who co-led the study.
Discovery of intriguing material behavior at small scales could reduce energy demands for computing.
As electronic devices become smaller and smaller, the materials that power them need to become thinner and thinner. Because of this, one of the key challenges scientists face in developing next-generation energy-efficient electronics is discovering materials that can maintain special electronic properties at an ultrathin size.
Advanced materials known as ferroelectrics present a promising solution to help lower the power consumed by the ultrasmall electronic devices found in cell phones and computers. Ferroelectrics—the electrical analog to ferromagnets—are a class of materials in which some of the atoms are arranged off-center, leading to a spontaneous internal electric charge or polarization. This internal polarization can reverse its direction when scientists expose the material to an external voltage. This offers great promise for ultralow-power microelectronics.