Was awarded jointly to John J. Hopfield and Geoffrey E. Hinton ‘for foundational discoveries and inventions that enable machine learning with artificial neural networks’
Category: robotics/AI – Page 331

The Yin and Yang of AI: Continuous vs. Discrete Information Models
Title: See…
Artificial intelligence software was used to enhance the grammar, flow, and readability of this article’s text.
Artificial intelligence systems aim to comprehend and convey information in increasingly human ways. Behind the scenes, different models represent that information using either continuous or discrete structures.

Robot placed under the control of a fungal overlord
Robots controlled by fungi, despite giving strong Last of Us vibes, are a good idea on paper; fungi are very easy to sustain and can live pretty much everywhere, including extreme environments like the Arctic, or even amid nuclear contamination.
A mushroom’s response to environmental changes can be used to control a robot.


AI Explained: AI Agents Are Quietly Taking Over Everyday Tasks
Although UBTech is leaving 10% of work for humans in management, other AI tech is being specifically developed for that niche: OpenAI’s new framework, Swarm, allows AI agents to collaborate and independently execute complex tasks, potentially boosting business efficiency.
Artificial intelligence agents are everywhere, quietly reshaping industries and automating tasks we didn’t think possible a few years ago. Unlike basic automation, these AI agents can handle complex jobs, think independently and learn from their environment. The result? Healthcare, finance and logistics businesses are seeing rapid gains in efficiency — and, in some cases, doing away with manual work altogether.
What are AI agents exactly? They’re software programs that carry out specific tasks without constant supervision. Whether handling customer requests, diagnosing medical conditions or predicting market trends, AI agents are versatile workhorses. Instead of waiting for humans to input every command, these agents operate autonomously, reacting to real-time data and adjusting their actions accordingly.
Microsoft recently unveiled new AI tools allowing healthcare organizations to build customized AI agents for appointment scheduling, clinical trial matching, and patient triage. These agents are designed to streamline workflows and improve efficiency, helping healthcare providers manage workloads and enhance patient care.

People are using Google study software to make AI podcasts—and they’re weird and amazing
“All right, so today we are going to dive deep into some cutting-edge tech,” a chatty American male voice says.
NotebookLM, which was originally marketed as a study tool, has taken a life of its own among users. The company is now working on adding more customization options, such as changing the length, format, voices, and languages, Martin said. Currently it’s supposed to generate podcasts only in English, but some users on Reddit managed to get the tool to create audio in French and Hungarian.
Yes, it’s cool—bordering on delightful, even—but it is also not immune from the problems that plague generative AI, such as hallucinations and bias.
Here are some of the main ways people are using NotebookLM so far.

Watch: Jetson founder pushes the limits of ‘Freestyle’ eVTOL agility
Jetson Founder Tomasz Patan is clearly getting very comfortable with the Jetson One eVTOL’s flight control system … Watch him wrench the controls around to show off how sharply – and safely – this thing can handle tight turns in flight.
Multicopter drones were revolutionary little gadgets when they started to appear on the scene for a number of reasons, but one was their highly automated fly-by-wire control systems. No human could manually control motor speeds on upwards of four rotors simultaneously, but a sensor-equipped flight control system certainly could – hence, drones like the DJI Phantom were able to automatically lift off and land, maintain altitude if required, and self-balance against wind gusts to hover in place, while also responding quickly to a pilot’s commands.
This is part of the promise with eVTOL aircraft – some of which, like the Jetson One, are really best described as great big multicopter drones a person can sit in.
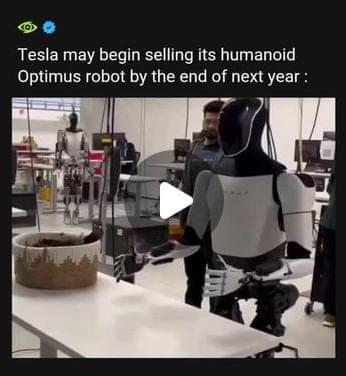
Elon Musk announced that Tesla may begin selling its humanoid Optimus robot by the end of next year
Predicting it could drive the carmaker towards a $25 trillion valuation.
Experts believe this ambitious claim is within the realm of possibility. Optimus is still in development but will enter production next year, with Musk stating that Tesla could have “a few thousand” units working in its factories, reaffirming his earlier timeline.
Airbus Successfully Completes First Lakota UH-72 Drone Helicopter Demo for US Marine Corps
Airbus U.S. Space & Defense announced on October 15, 2024, the successful completion of the first demonstration of the Lakota UH-72 drone helicopter for the U.S. Marine Corps, conducted at Marine Corps Air Station New River and Camp Lejeune. This demonstration showcased the capabilities of the Aerial Logistics Connector (ALC) system, designed to enhance logistical support in dispersed and challenging environments. As an autonomous platform, the Lakota UH-72 ensures a continuous supply flow without relying on traditional transportation methods, which are often vulnerable or limited.