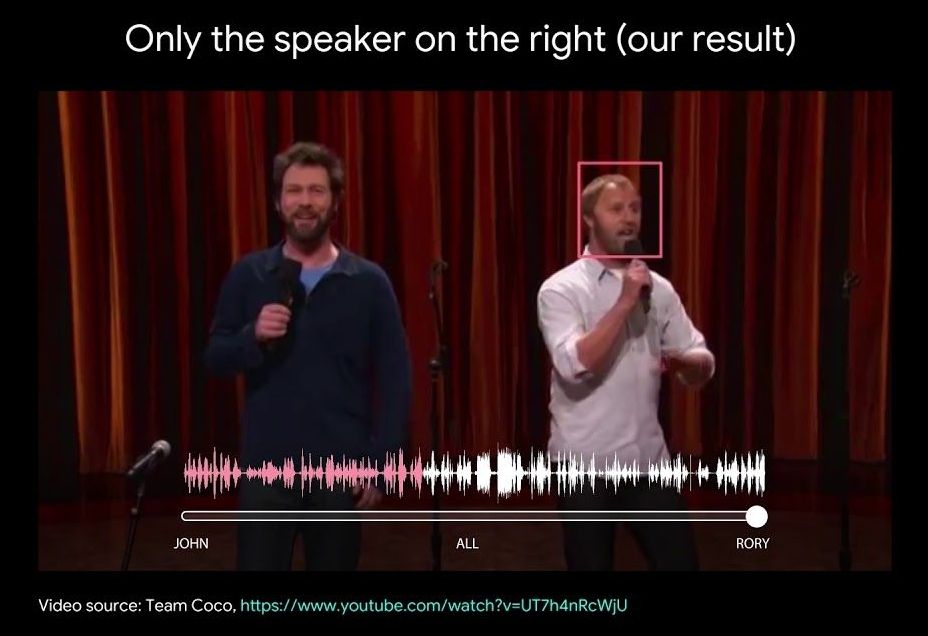
Humans are usually good at isolating a single voice in a crowd, but computers? Not so much — just ask anyone trying to talk to a smart speaker at a house party. Google may have a surprisingly straightforward solution, however. Its researchers have developed a deep learning system that can pick out specific voices by looking at people’s faces when they’re speaking. The team trained its neural network model to recognize individual people speaking by themselves, and then created virtual “parties” (complete with background noise) to teach the AI how to isolate multiple voices into distinct audio tracks.
The results, as you can see below, are uncanny. Even when people are clearly trying to compete with each other (such as comedians Jon Dore and Rory Scovel in the Team Coco clip above), the AI can generate a clean audio track for one person just by focusing on their face. That’s true even if the person partially obscures their face with hand gestures or a microphone.
Google is currently “exploring opportunities” to use this feature in its products, but there are more than a few prime candidates. It’s potentially ideal for video chat services like Hangouts or Duo, where it could help you understand someone talking in a crowded room. It could also be helpful for speech enhancement in video recording. And there are big implications for accessibility: it could lead to camera-linked hearing aids that boost the sound of whoever’s in front of you, and more effective closed captioning. There are potential privacy issues (this could be used for public eavesdropping), but it wouldn’t be too difficult to limit the voice separation to people who’ve clearly given their consent.









Comments are closed.