The researchers examine the effectiveness of watermarking in large language models (LLMs) and find that current methods, while promising, have serious weaknesses.
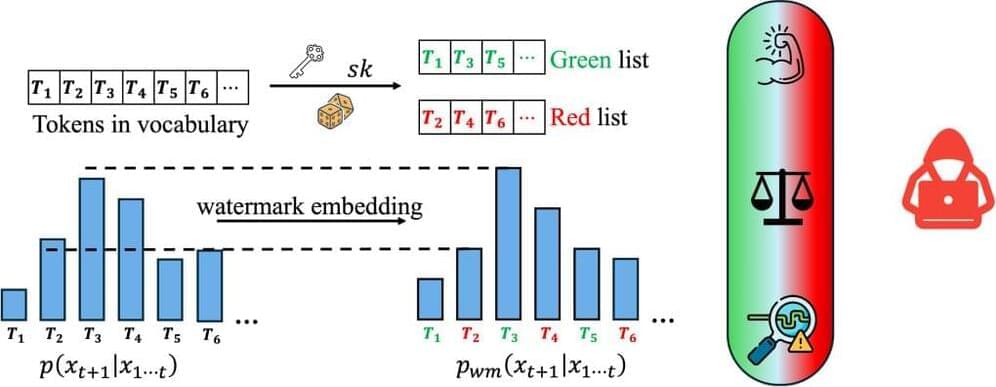
Advances in generative models have made it possible for AI-generated text, code, and images to mirror human-generated content in many applications. Watermarking, a technique that embeds information in the output of a model to verify its source, aims to mitigate the misuse of such AI-generated content. Current state-of-the-art watermarking schemes embed watermarks by slightly perturbing probabilities of the LLM’s output tokens, which can be detected via statistical testing during verification.
Unfortunately, our work shows that common design choices in LLM watermarking schemes make the resulting systems surprisingly susceptible to watermark removal or spoofing attacks—leading to fundamental trade-offs in robustness, utility, and usability. To navigate these trade-offs, we rigorously study a set of simple yet effective attacks on common watermarking systems and propose guidelines and defenses for LLM watermarking in practice.
Similar to image watermarks, LLM watermarking embeds invisible secret patterns into the text. Here, we briefly introduce LLMs and LLM watermarks. We use \(x\) to denote a sequence of tokens, \(x_i \in \mathcal{V}\) represents the \(i\)-th token in the sequence, and \(\mathcal{V}\) is the vocabulary. \(M_{\text{orig}}\) denotes the original model without a watermark, \(M_{\text{wm}}\) is the watermarked model, and \(sk \in \mathcal{S}\) is the watermark secret key sampled from \(\mathcal{S}\).









Leave a reply