Sep 13, 2024
AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments
Posted by Cecile G. Tamura in categories: biotech/medical, robotics/AI
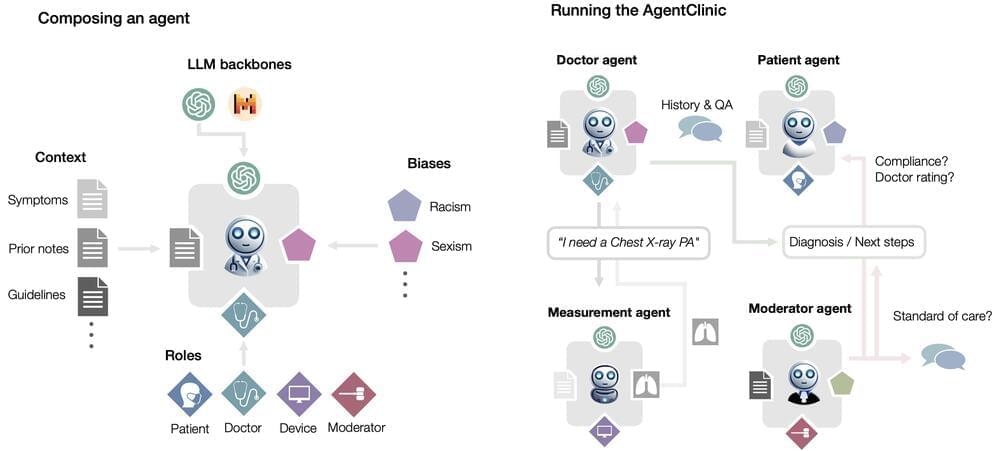
We present the first open-source benchmark to evaluate LLMs in their ability to operate as agents in simulated clinical environments. Diagnosing and managing a patient is a complex, sequential decision making process that requires physicians to obtain information—such as which tests to perform—and to act upon it. Recent advances in artificial intelligence (AI) and large language models (LLMs) promise to profoundly impact clinical care. However, current evaluation schemes overrely on static medical question-answering benchmarks, falling short on interactive decision-making that is required in real-life clinical work. Here, we present AgentClinic: a multimodal benchmark to evaluate LLMs in their ability to operate as agents in simulated clinical environments. In our benchmark, the doctor agent must uncover the patient’s diagnosis through dialogue and active data collection. We present two open benchmarks: a multimodal image and dialogue environment, AgentClinic-NEJM, and a dialogue-only environment, AgentClinic-MedQA. Agents in AgentClinic-MedQA are grounded in cases from the US Medical Licensing Exam~(USMLE) and AgentClinic-NEJM are grounded in multimodal New England Journal of Medicine (NEJM) case challenges. We embed cognitive and implicit biases both in patient and doctor agents to emulate realistic interactions between biased agents. We find that introducing bias leads to large reductions in diagnostic accuracy of the doctor agents, as well as reduced compliance, confidence, and follow-up consultation willingness in patient agents. Evaluating a suite of state-of-the-art LLMs, we find that several models that excel in benchmarks like MedQA are performing poorly in AgentClinic-MedQA. We find that the LLM used in the patient agent is an important factor for performance in the AgentClinic benchmark. We show that both having limited interactions as well as too many interaction reduces diagnostic accuracy in doctor agents.